XILINX ALVEO SOLUTIONS
We challenge
- Xilinx Alveo Accelerator Solutions
- 데이터 센터 워크로드 엑셀레이터 카드

Breathe New Life Into Your Data Center
데이터 센터 워크로드 가속화
- 데이터베이스 검색 및 분석 90 X
- 금융 자산 리스크 예측 89 X
- 실시간 머신 러닝 20 X
- 비디오 처리 및 트랜스코딩 12 X
- 유전체 분석 10 X
-

Xilinx ® Alveo™ U50 | U200 | U250 | U280
- Xilinx ® Alveo™ 데이터 센터 엑셀레이터 카드는 끊임없이 변화하는
데이터센터의 워크로드 요건에 발빠르게 대응하기 위해 개발되었습니다.
머신러닝의 추론, 비디오 트랜스 코딩, 데이터베이스 검색/분석 등의
고성능이 요구되는 워크로드에 대해 CPU 대비 최대 90배의 성능을
제공합니다.
데이터센터의 워크로드가 첨단 알고리즘으로 가속화 되면서 기능이
고정되어있는 GPU와 ASIC의 현재의 실리콘 설계주기로는 따라잡을 수
없는 상황이되고 있습니다.
Xilinx 16nm UltraScale™ 아키텍처 기반의 Alveo™ 엑셀레이터 카드는
지속적인 알고리즘 최적화 요건에 유연하게 적응할 수 있으며 전체 비용을
절감하고 모든 데이터센터 워크로드에 대응 가능합니다.
Alveo 엑셀레이터 카드를 고객이 쉽게 이용할 수 있도록 Xilinx®는
데이터센터 워크로드를 해결하는 에코파트너의 솔루션을 제안합니다.
또한 Xilinx®의 애플리케이션 개발자 도구 (SDAccel™) 및 맞춤형 솔루션인
Machine Learning Suite 도구를 제공하여 개발자가 차별화된
애플리케이션을 빠르게 출시 할 수 있도록 지원하고 있습니다.
주요 특징
-
Fast - Highest Performance
주요 워크로드 처리에서 CPU 대비
1/3 비용으로 성능 최대 90배 향상GPU 기반 솔루션 대비 추론 처리량 4배 이상,
응답속도 3배 향상 -
Adaptable - Accelerate Any Workload
하나의 엑셀레이터 카드로 머신러닝의
추론부터 비디오 트랜스 코딩까지 모든
워크로드에 대응빠르게 진화하는 알고리즘에 대응하기 위해
재 프로그래밍이 가능한 FPGA를 사용 -
Accessible - Cloud ↔ On-Premises Mobility
클라우드 또는 온프레미스에서 자유롭게
구축하고 애플리케이션에 상황에 맞춰
상호 이동 가능에코파트너의 애플리케이션 또는 Xilinx의
개발자 도구를 사용하여 직접 구축 가능
Increase Real-Time Machine Learning* Throughput by 20X Reduce ML Inference Latency by 3X
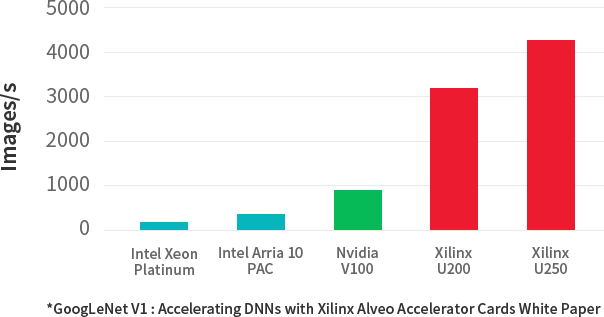
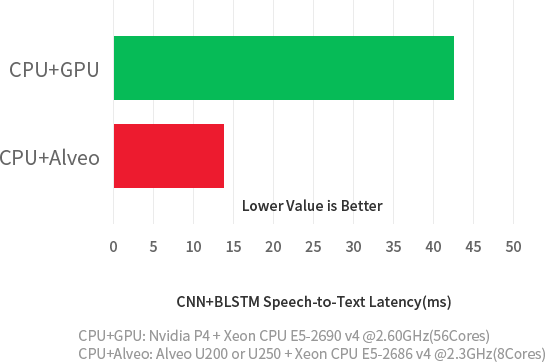
-

ALVEO U50
16,2 Peak INT8 TOPs
8 GB HBM2 Memory
460 GB/s HBM2 Memory B/W
24 TB/s Internal SRAM B/W
872K LUTs
-

ALVEO U200
18,6 Peak INT8 TOPs
64 GB DDR Memory
77 GB/s DDR Memory B/W
31 TB/s Internal SRAM B/W
892K LUTs
-

ALVEO U250
33,3 Peak INT8 TOPs
64 GB DDR Memory
77 GB/s DDR Memory B/W
38 TB/s Internal SRAM B/W
1.341K LUTs
-

ALVEO U280
24,5 Peak INT8 TOPs
32 GB DDR Memory
38 GB/s DDR Memory B/W
8 GB/s HBM2 Memory
460 GB/s HBM2 Memory B/W
35 TB/s Internal SRAM B/W
1.079K LUTs
ALVEO 를 이용한 데이터 센터 워크로드 가속화
컴퓨팅 스토리지 가속화
Alveo U50은 빠르고 유연한 압축 가속
비용절감 - Alveo U50 압축 가속으로 33% 비용절감
(10GB/Sec처리량 2:1 압축 기준)
GZIP Compression Throughput (GB/sec)

Intel Skylake-SP 6152 @2.10GHz CPU (Ubuntu 16.04)
GB/s compression per CPU core = .0229. Alveo U50 = 10GB/s (estimate)
금융 시뮬레이션 - 그리드 컴퓨팅
가장 빠른 통찰력
운영 비용 절감 및 최대 전력 효율
빠른 응답 시간으로 일관된 성능
Monte Carlo SimulationPerformance&Efficiency (paths/sec/W)

Intel Xeon E5-2697 v4 GCC 5.4.0 Nvidia Tesla V100 16GB PCIe CUDA 10.1 / GCC 5.4.0
Xilinx Alveo U50 SDAccel 2018.3 (estimate)
초 저 지연 네트워킹
대기시간 20배 감소
Alveo U50 은 CPU 지연시간 10ms 대비 500ns 미만의
트랜잭션 시간
동일 시간에 빠른 처리
Speedup of Trading TimingMarket data to TCP message(speedup)

Alveo U50 latency is<0.5us, CPU latency is10us. Measured from star ofpacket ino Tick
(Market Da) toSart ofPacket oun theorde toSart ofPacket Ouon theOrde (stimate)
딥러닝 추론 가속화
10배 높은 처리량(초당 변화된 문자)
대기시간 25배 감소
노드당 전력 효율성 대폭 향상
Speech Translation ThroughputTransformer NMT (symbols/sec speedup)

Perfomance ofAlveo U50 –with both Alveo U50 and
Tesla T4runig (B=2, L=8), Tesla T4(B=8, L=8) (estimate)
데이터 분석 가속화
CPU 대비 높은 쿼리 처리량 및 응답시간
노드당 비용 효율성 향상
윤영 비용 절감
Database Query Acceleration (TPC-H Query 5)
(Queries / hour speedup)
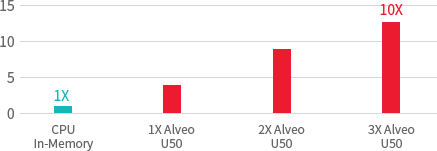
CPU Query time =210ms, 34kquery/h. Alveo U50=24ms, 150k query/h
INTEL® XEON® PLATINUM 8260 PROCESOR (35.7M Cache, 2.40 GHz) 24core
데이터 센터 워크로드용 ECO 파트너 솔루션
Xilinx® Alveo™ 데이터 센터 엑셀레이터 카드는 폭넓은 ECO 파트너 솔루션으로 대폭적인 성능향상을 이룰 수 있는
동시에 재구성 가능한 특성을 살려 최신 데이터센터의 다양한 워크로드에 대응할 수 있습니다.
| 마켓 | ECO 파트너 | CPU 비교 | 애플리케이션 설명 | |
|---|---|---|---|---|
 데이터베이스 데이터베이스 |
 |
Black LYNX | 90 X | Elasticsearch 액셀러레이터 Java, C/C++, Python, ODBC/JDBC, Spark, JSON, etc 와 연동된 Elasticsearch 와 빅 데이터 해석 엔진입니다. |
 |
TITAN | - | 네트워크 보안 및 데이터 수집 가속기 REP API 에서 규정한 최대 100 만 패턴의 검색 규칙을 구현 가능한 1-100Gbps 처리량 가속기입니다. |
|
 |
bigstream | 2 - 30 X | 빅 데이터 분석 가속기 JSON, CSV, Parquet & Avro 의 데이터 Parsing, ELT / ETL data 클렌징 및 엔리치 가속기입니다. |
|
 |
VITESSEDATA | 86 X | 오픈 소스용 GPDB(GreenplumData Base project)에 대응하는 데이터베이스 쿼리 가속기 및 데이터베이스용 머신러닝 가속기를 제공합니다. | |
 |
ALGO LOGIC | 100 - 1000 X | 고성능 KVS(Key-Value-Store) 테이블 검색을 이용한 텔레콤 디렉토리, 인터넷 프로토콜 전송 테이블 및 중복 제거 저장 시스템 가속기입니다. | |
 |
XELERA | 50 X | XeleraANALYTICS 에 의한 Apache Spark MLlib 가속기 FPGA 개발 지식이 없이 Apache SparkMLlib 을 이용하는 것만으로도 가속을 할 수 있습니다. | |
 머신러닝 머신러닝 |
 |
Mipsology | 100 - 500 X | 이미지 Classfication 을 위한 신경망 FPGA 지식을 필요로 하지 않으며 Caffe 2, MXNET 및TensorFlow 프레임 워크를 사용하여 학습이 완료된 네트워크를 구현할 수 있는 가속기입니다. |
 |
Sum Up | 100 X | 구조화되지 않은 데이터베이스에서 데이터를 추출·분석을 수행하는 가속기인 분석 알고리즘 Nucleus 는 별도의 교육과정 없이 쉽게 적용이 가능합니다. | |
 이미지 / 동영상 처리 이미지 / 동영상 처리 |
 |
NGCodec | 10 X | 적응형 비트레이트 비디오 트랜스코딩 엔진 FFMPEG 플러그인 & 방송 품질 대응 H.265, HEVCEncode 엔진으로 최대 32 스트림을 동시 인코딩 |
 |
Skreens | 5 X | 방송, 게임, 모니터, 미디어 산업 비디오 가속기 4ch 1080p60 스트림을 멀티 레이어 표시 · 배치 · 투명화 처리, 또는 영상 처리 및 기계 학습을 통합 할 수 있습니다. | |
 |
CTACCEL | 10 X | 이미징 프로세싱 가속기 사용자에 맞는 썸네일 생성, 리사이즈, 워터마크, 색상 조정을 JPEG 디코딩 리사이즈 이미지 처리용 액셀러레이터 |
|
 금융 / 증권 금융 / 증권 |
 |
MAXELER | 100 X | Real Time Risk, CVA, ISDA SIMM 및 CME Clearing, 시장 데이터 등을 포함하는 종합 금융 위험 평가 가속기입니다. |
 생명공학 생명공학 |
 |
FALCON | 10 X | Real Time Risk, CVA, ISDA SIMM 및 CME Clearing, 시장 데이터 등을 포함하는 종합 금융 위험 평가 가속기입니다. |
제품 문의
TEL : 02-3463-5805
FAX : 02-3463-5804
E-mail : sys-sales@makus.co.kr