AI, DL Solutions
We challenge
- Xilinx Alveo Accelerator Solutions
- Accelerator Cards for Data Center Workloads

Breathe New Life Into Your Data Center
ADAPTABLE TO ANY WORKLOAD
- Database Search & Analytics 90 X
- Financial Computing 89 X
- Machine Learning 20 X
- Video Processing/Transcoding 12 X
- Genomics 10 X
-

Xilinx ® Alveo™ U50 | U200 | U250 | U280
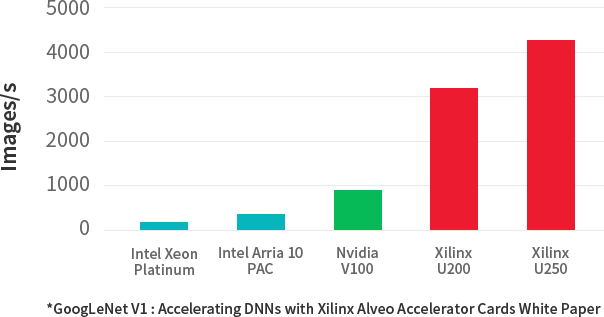
- Xilinx® Alveo™ Data Center accelerator cards are designed to meet the constantly changing needs of the modern Data Center,providing up to 90X performance increase over CPUs for common workloads, including machine learning inference, video transcoding,and database search and analytics.
With complex algorithms evolving faster than silicon design cycles,it’s impossible for fixed function GPU and ASIC devices to keep pace. Built on Xilinx 16nm UltraScale™ architecture, Alveo accelerator cards provide reconfigurable acceleration that can adapt to continual algorithm optimizations, supporting any workload type while reducing overall cost of ownership.
Enabling Alveo accelerator cards is a growing ecosystem of Xilinx and partner applications for common Data Center workloads. For custom solutions, Xilinx’s Application Developer tool (SDAccel™ tool) and Machine Learning Suite provide the tools for developers to bring differentiated applications to market.
HIGHLIGHTS
-
Fast - Highest Performance
Up to 90X higher performance than CPUs
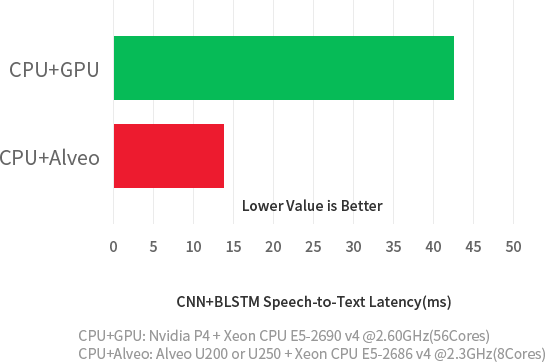
on key workloads at 1/3 the costOver 4X higher inference throughput and 3X latency advantage over GPU-based solutions
-
Adaptable - Accelerate Any Workload
Machine learning inference to video
processing to any workload using the same accelerator cardAs workloads algorithms evolve, use
reconfigurable hardware to adapt faster than
fixed-function accelerator card product cycles -
Accessible - Cloud ↔ On-Premises Mobility
Deploy solutions in the cloud
or on-premises interchangeably,
scalable to application requirementsApplications available for common
workloads, or build your own with the application developer tool
Increase Real-Time Machine Learning* Throughput by 20X Reduce ML Inference Latency by 3X
-

ALVEO U50
16,2 Peak INT8 TOPs
8 GB HBM2 Memory
460 GB/s HBM2 Memory B/W
24 TB/s Internal SRAM B/W
872K LUTs
-

ALVEO U200
18,6 Peak INT8 TOPs
64 GB DDR Memory
77 GB/s DDR Memory B/W
31 TB/s Internal SRAM B/W
892K LUTs
-

ALVEO U250
33,3 Peak INT8 TOPs
64 GB DDR Memory
77 GB/s DDR Memory B/W
38 TB/s Internal SRAM B/W
1.341K LUTs
-

ALVEO U280
24,5 Peak INT8 TOPs
32 GB DDR Memory
38 GB/s DDR Memory B/W
8 GB/s HBM2 Memory
460 GB/s HBM2 Memory B/W
35 TB/s Internal SRAM B/W
1.079K LUTs
SUPERCHARGING A BROAD RANGE OF DATA CENTER APPLICATIONS
Computational Storage Acceleration
Financial Simulation – Grid Computing
Ultra-Low Latency Networking
Deep Learning Inference Acceleration
Data Analytics Acceleration
Computational Storage Acceleration
˃ Alveo U50 delivers fastest and most flexible compression/decompression acceleration
˃ Lower cost – Alveo U50 accelerated compression delivers 33% lower cost.
(Based on 10GB/sec throughput and 2:1 compression)
GZIP Compression Throughput (GB/sec)

Intel Skylake-SP 6152 @2.10GHz CPU (Ubuntu 16.04)
GB/s compression per CPU core = .0229. Alveo U50 = 10GB/s (estimate)
Financial Simulation – Grid Computing
Fastest time to insight
Reduced operational costs and maximum power efficiency
Deterministic latency delivers consistent performance
Monte Carlo SimulationPerformance&Efficiency (paths/sec/W)

Intel Xeon E5-2697 v4 GCC 5.4.0 Nvidia Tesla V100 16GB PCIe CUDA 10.1 / GCC 5.4.0
Xilinx Alveo U50 SDAccel 2018.3 (estimate)
Ultra-Low Latency Networking
20x lower latency
Alveo U50 delivers sub-500ns trading time vs CPU latency of 10us
Deterministic throughput timing
Speedup of Trading TimingMarket data to TCP message(speedup)

Alveo U50 latency is<0.5us, CPU latency is10us. Measured from star ofpacket ino Tick
(Market Da) toSart ofPacket oun theorde toSart ofPacket Ouon theOrde (stimate)
Deep Learning Inference Acceleration
10x Higher throughput – translated symbols per second
25x lower latency
Significantly improved power efficiency per node
Speech Translation ThroughputTransformer NMT (symbols/sec speedup)

Perfomance ofAlveo U50 –with both Alveo U50 and
Tesla T4runig (B=2, L=8), Tesla T4(B=8, L=8) (estimate)
Data Analytics Acceleration
Higher query throughput & response time than CPU
Higher cost effectiveness per node
Reduced Operational cost
Database Query Acceleration (TPC-H Query 5)
(Queries / hour speedup)
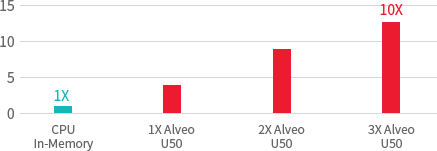
CPU Query time =210ms, 34kquery/h. Alveo U50=24ms, 150k query/h
INTEL® XEON® PLATINUM 8260 PROCESOR (35.7M Cache, 2.40 GHz) 24core
ECO Partner Solutions for Data Center Workloads
Xilinx® Alveo™ Accelerator Cards can deliver significant performance gains across a wide range of applications while leveraging its reconfigurable characteristics to support a wide variety of workloads in the latest data center.
| Market | ECO Partner | CPU comparison | Application | |
|---|---|---|---|---|
 Database Database |
 |
Black LYNX | 90 X | High Speed Elastic Search Accelerator It is an Elastic Search and big data analysis engine linked to Java, C/C++, Python, ODBC/JDBC, Spark, JSON, etc. |
 |
TITAN | - | Network security & Data collection Accelerator It is a 1-100 Gbps throughput accelerator that can implement up to 1 million patterns of search rules specified by REP API |
|
 |
bigstream | 2 - 30 X | Big data analysis Accelerator This is JSON, CSV, Parquet & Avro data Parsing, ELT/ETL data cleansing and enrich accelerator. |
|
 |
VITESSEDATA | 86 X | Provides an open source GPDB(GreenplumData Base project) enabled database querier and machine learning accelerator for databases | |
 |
ALGO LOGIC | 100 - 1000 X | Key-Value Store (KVS) is an essential service for multiple applications. Telecom directories, Internet Protocol forwarding tables, and de-duplicating storage systems | |
 |
XELERA | 50 X | Xelera ANALTYICS Apache Spark MLlib Accelerator Even if you don't have the knowledge of FPGA development, you can use Apache Spark MLlib as usual to accelerate | |
 머신러닝 머신러닝 |
 |
Mipsology | 100 - 500 X | NEURAL NETWORK FOR IMAGE CLASSIFICATION Accelerator for implementing learned networks using Cafe/2, MXNET, and TensorFlow frameworks without requiring FPGA knowledge |
 |
Sum Up | 100 X | An accelerator that extracts and analyzes data from unstructured databases, the analytical algorithm Nucleus employs unsupervised learning, and is easy to introduce even non-technicians | |
 이미지 / 동영상 처리 이미지 / 동영상 처리 |
 |
NGCodec | 10 X | ADAPTIVE BIT RATE VIDEO TRANSCODING ENGINE An H.265 with FFMPEG plug-in and broadcast quality H.265, HEVCEncode engine that can simultaneously encode up to 32 streams |
 |
Skreens | 5 X | Broadcast, gaming, monitoring and media video accelerator 4ch Multi-layer View, Deploy, Transparent 1080p60 Streams, and integrate imaging and machine learning | |
 |
CTACCEL | 10 X | Imaging Processing Accelerator The accelerator for generating thumbnails, resizing, watermarking and adjusting colors according to users is JPEG decode→resize→image processing→Lepton encoding. |
|
 금융 / 증권 금융 / 증권 |
 |
MAXELER | 100 X | Real Time Risk, Credit Assessment Adjustment (CVA), Evidence Regulation (ISDA SIMM and CME Clearing), and a comprehensive finance risk assessment accelerator that includes market data, etc. |
 생명공학 생명공학 |
 |
FALCON | 10 X | HIGH SPEED GENOME ANALYSIS ENGINE This is an acceleration solution that captures Row data from sequencers to accelerate GAKT Ver4.0 compliant genomic analysis pipeline processing and to support custom flows other than GAKT flows. |
Product Inquiry
TEL : +82-2-3463-5805
FAX : +82-2-3463-5804
E-mail : sys-sales@makus.co.kr